この記事は
Go Advent Calendar 2020 4日目の記事となる。
今回はGoでベンチマークの結果を可視化する方法をまとめる。
また、可視化した結果を用いてgoroutine最適化のリファクタリングをしてみる。
TL;DR
- Goはインストールするだけでベンチマークが実行できる
benchstatコマンドを使うとベンチマーク結果をよしなにして確認できる。go tool traceコマンドを使うと、goroutineの実行状況も可視化できる
推測するな計測せよ
「推測するな、計測せよ」はGoのオリジナル作者の1人、ロブ・パイク氏の「Cプログラミングに関する覚書」から言われている言葉だ。
氏の哲学が反映されているからか、GoはGoをインストールすればベンチマークを実行できる。
(benchstatコマンドは追加インストールが必要になるが、)今回はこのベンチマークの結果をより有効活用していく方法を実際にリファクタリングを繰り返しながら紹介する。
計測で利用するツール
GoはGo本体をインストールすればテストを実行できる。それと同時にベンチマークも実行可能になる。 今回はこのベンチマークの計測結果を次のツールを使って可視化していく。
benchstatgo tool trace
実行環境と対象とする関数
本記事の実行環境は次の通り。
- macbook Pro 2019 13inch(論理8コア)
- macOS Mojave(10.14.6)
- go version go1.15.5 darwin/amd64
ベンチマークで実行する対象は一言でいうと、「非同期で実行可能な大量の重たい処理」だ。
具体的には次のフィボナッチ関数を1,000回実行する。
フィボナッチ関数(数値計算関数)を選んだ理由はgoroutineによるメモリ利用状況なども確認しやすいため。
func fibonacci(n int) int {
if n < 2 {
return n
}
f1, f0 := 1, 0
fn := f1 + f0
for i := n; i >= 2; i-- {
fn = f1 + f0
f1, f0 = fn, f1
}
return fn
}
func fibonacciTask() int {
return fibonacci(1_000_000) // million
}
上記の計算量の多い関数を1,000個生成し、execute関数ですべて実行終了するまでの時間を計測する。
type task func() int
func genTasks() []task {
const n = 1_000
ts := make([]task, 0, n)
for i := 0; i < n; i++ {
ts = append(ts, fibonacciTask)
}
return ts
}
ベンチマーク関数は素朴に次のように実装する。
func BenchmarkFibonacci(b *testing.B) {
ts := genTasks() // 1,0000個のタスクを用意
b.ResetTimer()
for i := 0; i < b.N; i++ {
execute(ts)
}
}
逐次実行結果をベンチマークする
まずは何も考えずに逐次実行の処理を書いてベンチマークを実行してみる。
本来は「単位時間あたり」の実行回数でベンチマークをすべきだろうが、後にgoroutineの実行状況を確認したいので、
あえて「1回実行(-benchtime 1x)」するベンチマークを「10回(-count 10)」実行してみる。
これに加え、メモリ利用状況を可視化する-benchmem、実行トレースを保存しておく-traceオプションを利用する。
$ go test -bench . -benchmem -benchtime 1x -count 10 -trace first.trace > first.out
$ cat first.out
goos: darwin
goarch: amd64
pkg: github.com/budougumi0617/til/go/goroutine/benchstat
BenchmarkFibonacci-8 1 504299984 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 501610707 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 500481271 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 499073201 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 507238465 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 507779247 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 505474920 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 501243584 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 504582972 ns/op 0 B/op 0 allocs/op
BenchmarkFibonacci-8 1 504731530 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/budougumi0617/til/go/goroutine/benchstat 10.110s
benchstatを使ってベンチマーク結果を分析する
benchstatコマンドはベンチマークの出力結果をよしなに集計してくれるコマンドだ。
次のgo getコマンドで取得できる。
$ go get -u golang.org/x/perf/cmd/benchstat
引数としてベンチマーク実行結果を保存したファイルをひとつ渡すと、平均値などを集計してくれる。
$ benchstat first.out
name time/op
Fibonacci-8 504ms ± 1%
name alloc/op
Fibonacci-8 0.00B
name allocs/op
Fibonacci-8 0.00
素朴な実装なexecute関数はおおよそ500ms(誤差1%範囲)で実行が完了している。メモリ利用はゼロだ。
ここからベンチマークの結果を確認しながらリファクタリングを始める。
goroutineを使って並行処理をする
まずsync.WaitGroupを使って並行処理をしてみる。
func execute(ts []task) {
var wg sync.WaitGroup
for _, t := range ts {
wg.Add(1)
go func(t task) {
defer wg.Done()
t()
}(t)
}
wg.Wait()
}
ひたすらgoroutineを起動してそれぞれのタスクを並行実行していく処理だ。 ただし、実行環境は8コアなので、同時に実行できるgoroutineの数は最大で8だ。
ベンチマーク関数、(ファイル名以外の)実行引数は変更せずに再度ベンチマークを実行する。
$ go test -bench . -benchmem -benchtime 1x -count 10 -trace second.trace > second.out
$ cat second.out
goos: darwin
goarch: amd64
pkg: github.com/budougumi0617/til/go/goroutine/benchstat
BenchmarkFibonacci-8 1 88846592 ns/op 153168 B/op 1319 allocs/op
BenchmarkFibonacci-8 1 79973516 ns/op 8024 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 84371205 ns/op 8024 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 79913393 ns/op 8112 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 79979158 ns/op 13776 B/op 1016 allocs/op
BenchmarkFibonacci-8 1 83886835 ns/op 8024 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 83636550 ns/op 8120 B/op 1003 allocs/op
BenchmarkFibonacci-8 1 82550012 ns/op 8112 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 83379931 ns/op 8112 B/op 1002 allocs/op
BenchmarkFibonacci-8 1 82248013 ns/op 8016 B/op 1001 allocs/op
PASS
ok github.com/budougumi0617/til/go/goroutine/benchstat 1.698s
benchstatコマンドで実行結果を比較する
実装を変更した結果パフォーマンスはどのように変わったのだろうか?
2つの実行結果が揃えば、benchstatコマンドで差異を確認することができる。
$ benchstat first.out second.out
name old time/op new time/op delta
Fibonacci-8 504ms ± 1% 83ms ± 7% -83.54% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
Fibonacci-8 0.00B 8068.00B ± 1% +Inf% (p=0.000 n=10+8)
name old allocs/op new allocs/op delta
Fibonacci-8 0.00 1002.00 ± 0% +Inf% (p=0.000 n=10+8)
平均504msかかっていた実行時間が、平均83msになり、83%改善された! メモリまわりに関しては元が0だったので、増加量がInf%となってしまっている。
go tool traceコマンドを使ってgoroutineの実行状況を可視化する
次にgoroutineの実行状況を確認してみる。
-traceコマンドで保存していたトレースファイルをgo tool traceコマンドで可視化すれば、ベンチマーク実行中のgoroutineの実行状況が確認できる。
go tool traceコマンドでwebサーバを起動するには次の通り。
$ go tool trace --http localhost:6061 second.trace
http://127.0.0.1:6061/traceで可視化されたgoroutineの実行状況を確認できる(図の青いグラフ)。
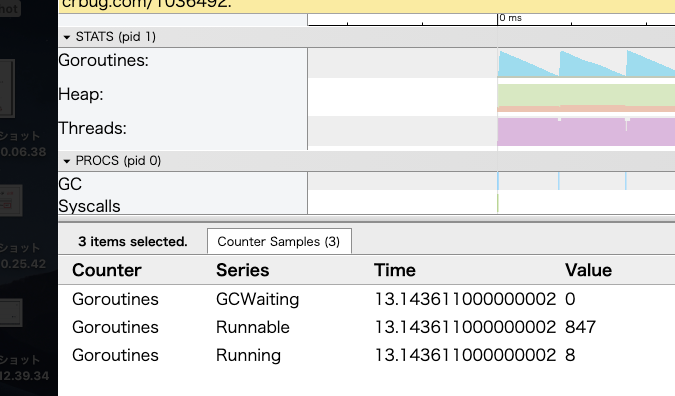
何も考えずにタスクの数だけgorotuineを起動しているので、1,000弱のgoroutineが最初に積まれ、(実行環境が論理8コアなので、)8 goroutineずつ消化されている。
もし待機中のgoroutineが気になるならば、goroutineの同時起動数を制御する必要がある。
goroutineの同時実行数を制御してみる
簡単にgoroutineの起動を制御すると次のようになる。
goroutine同時実行上限(GOMAXPROCS)分のgoroutineしか起動させない。
func execute(ts []task) {
sem := make(chan struct{}, runtime.GOMAXPROCS(0))
for _, t := range ts {
sem <- struct{}{}
go func(t task) {
t()
<-sem
}(t)
}
}
先ほど同様にベンチマークを実行する。
$ go test -bench . -benchmem -benchtime 1x -count 10 -trace third.trace > third.out
$ cat third.out
goos: darwin
goarch: amd64
pkg: github.com/budougumi0617/til/go/goroutine/benchstat
BenchmarkFibonacci-8 1 132919775 ns/op 11680 B/op 1011 allocs/op
BenchmarkFibonacci-8 1 132907422 ns/op 8992 B/op 1004 allocs/op
BenchmarkFibonacci-8 1 132938626 ns/op 13296 B/op 1016 allocs/op
BenchmarkFibonacci-8 1 129603855 ns/op 11968 B/op 1011 allocs/op
BenchmarkFibonacci-8 1 133638771 ns/op 10432 B/op 1007 allocs/op
BenchmarkFibonacci-8 1 131900001 ns/op 8608 B/op 1003 allocs/op
BenchmarkFibonacci-8 1 131738196 ns/op 9664 B/op 1005 allocs/op
BenchmarkFibonacci-8 1 132454023 ns/op 8976 B/op 1004 allocs/op
BenchmarkFibonacci-8 1 142136062 ns/op 11344 B/op 1005 allocs/op
BenchmarkFibonacci-8 1 130519934 ns/op 8896 B/op 1003 allocs/op
PASS
ok github.com/budougumi0617/til/go/goroutine/benchstat 2.699s
待ち合わせをするようにしたので実行時間はシンプルなsync.WaitGroupの実装よりも悪化してしまった。
利用メモリ量はchannel利用分だけやや悪化、アロケーション回数は変わらずとなっている。
benchstat second.out third.out
name old time/op new time/op delta
Fibonacci-8 82.9ms ± 7% 132.1ms ± 2% +59.35% (p=0.000 n=10+9)
name old alloc/op new alloc/op delta
Fibonacci-8 8.07kB ± 1% 10.39kB ±28% +28.73% (p=0.000 n=8+10)
name old allocs/op new allocs/op delta
Fibonacci-8 1.00k ± 0% 1.01k ± 1% +0.49% (p=0.000 n=8+10)
ただ、goroutineの同時実行という観点では少なくできたようだ。
$ go tool trace --http localhost:6061 third.trace
実行待機中(Runnable)なgoroutineはほぼないままベンチマークが進行している。
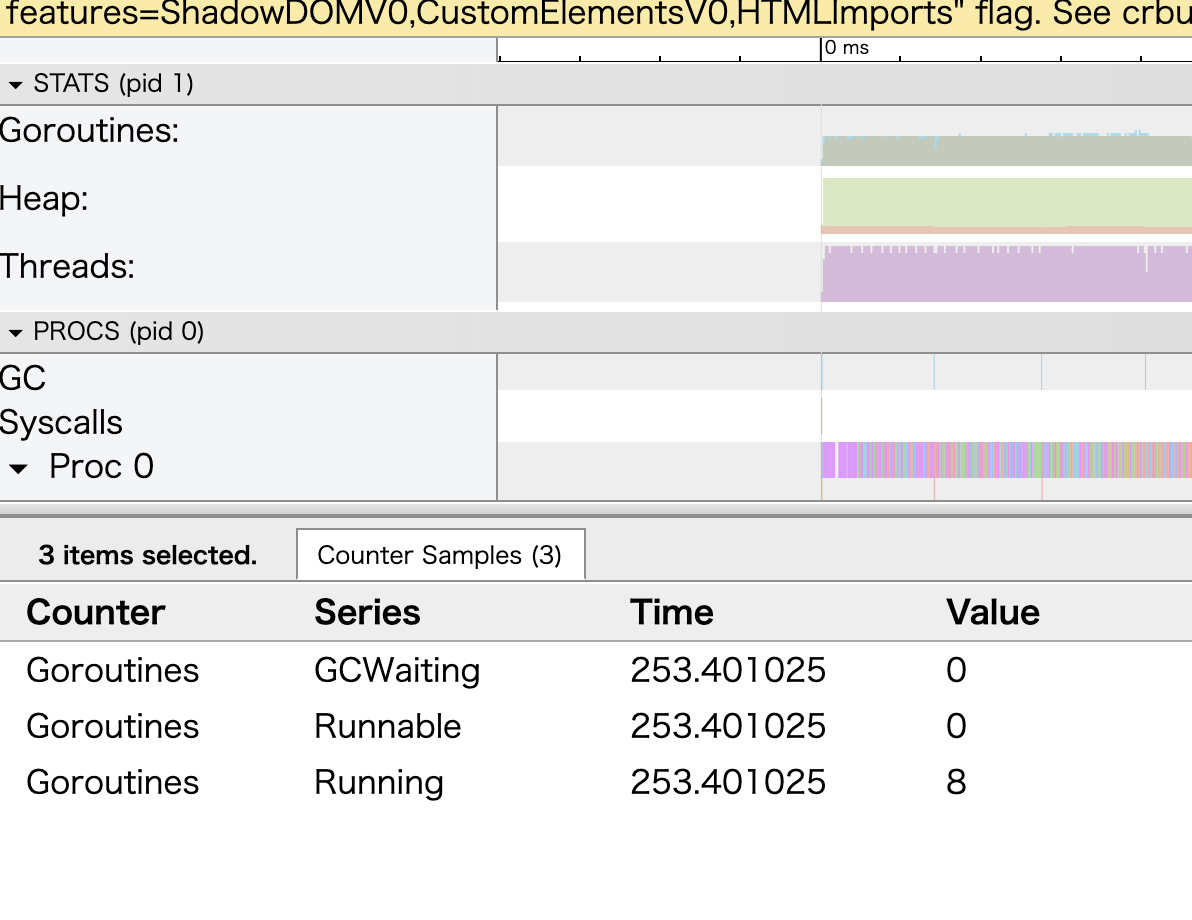
しかし、遅くなっては意味がないのでさらにリファクタリングする。
さらにチューニングする
アロケーションの回数が減らないのは毎回新しいgoroutineを起動しているからだ。
ワーカースレッドパターンを実装して、一度起動したgoroutineを最後まで使い、channelを使ってタスクを流し込むように実装し直す。
func execute(ts []task) {
n := runtime.GOMAXPROCS(0)
queue := make(chan task, n)
var wg sync.WaitGroup
for i := 0; i < n; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for {
select {
case t, ok := <-queue:
if !ok {
return
}
t()
}
}
}()
}
for _, t := range ts {
queue <- t
}
close(queue)
wg.Wait()
}
4回目の実装結果のベンチマークは次の通り。
$go test -bench . -benchmem -benchtime 1x -count 10 -trace fourth.trace > fourth.out
$ cat fourth.out
goos: darwin
goarch: amd64
pkg: github.com/budougumi0617/til/go/goroutine/benchstat
BenchmarkFibonacci-8 1 128735610 ns/op 3600 B/op 25 allocs/op
BenchmarkFibonacci-8 1 123402563 ns/op 3216 B/op 21 allocs/op
BenchmarkFibonacci-8 1 123261874 ns/op 1488 B/op 18 allocs/op
BenchmarkFibonacci-8 1 123670226 ns/op 1392 B/op 17 allocs/op
BenchmarkFibonacci-8 1 125857013 ns/op 3216 B/op 21 allocs/op
BenchmarkFibonacci-8 1 124957413 ns/op 1008 B/op 16 allocs/op
BenchmarkFibonacci-8 1 127014103 ns/op 3024 B/op 19 allocs/op
BenchmarkFibonacci-8 1 129873632 ns/op 1200 B/op 15 allocs/op
BenchmarkFibonacci-8 1 124401961 ns/op 3312 B/op 22 allocs/op
BenchmarkFibonacci-8 1 123169638 ns/op 432 B/op 13 allocs/op
PASS
ok github.com/budougumi0617/til/go/goroutine/benchstat 2.550s
今までのすべての実行結果の平均値をbenchstatコマンドで並べると次の通り
$ benchstat first.out second.out third.out fourth.out
name \ time/op first.out second.out third.out fourth.out
Fibonacci-8 504ms ± 1% 83ms ± 7% 132ms ± 2% 123ms ± 1%
name \ alloc/op first.out second.out third.out fourth.out
Fibonacci-8 0.00B 8068.00B ± 1% 10385.60B ±28% 3225.14B ±37%
name \ allocs/op first.out second.out third.out fourth.out
Fibonacci-8 0.00 1002.00 ± 0% 1006.90 ± 1% 21.22 ±43%
4回目の実装は実行結果にばらつきはあるものの、そこそこのメモリ使用量と実行速度になった。
逐次実行と比較して75%以上高速化できた。
$ benchstat first.out fourth.out
name old time/op new time/op delta
Fibonacci-8 504ms ± 1% 123ms ± 1% -75.51% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
Fibonacci-8 0.00B 3225.14B ±37% +Inf% (p=0.000 n=10+7)
name old allocs/op new allocs/op delta
Fibonacci-8 0.00 21.22 ±43% +Inf% (p=0.000 n=10+9)
素朴な並行処理と比較すると、実行時間が50%ほど増加した代わりにメモリ利用状況がかなりカイゼンしている。
$ benchstat second.out fourth.out
name old time/op new time/op delta
Fibonacci-8 82.9ms ± 7% 123.3ms ± 1% +48.83% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
Fibonacci-8 8.07kB ± 1% 3.23kB ±37% -60.03% (p=0.000 n=8+7)
name old allocs/op new allocs/op delta
Fibonacci-8 1.00k ± 0% 0.02k ±43% -97.88% (p=0.000 n=8+9)
go tool traceコマンドで確認すると待機中のgoroutineの数も少ない。
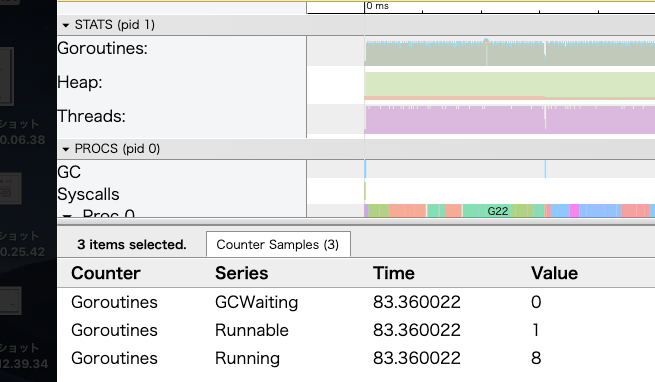
あとは、計測結果から何を優先するかによって、どの実装を採用するか決めればよい。
終わりに
今回はベンチマークの結果を確認しながらgoroutineチューニングをしてみた。
ただし、今回の内容ははっきり言ってかなり恣意的なチューニング対象だった(非同期で実行可能で、コア数の数百倍の重たい処理)。
(計測するのは大事だが、)常に今回のコードの修正が正しいわけではない。
ここまでやって何だが、goroutineのメモリ利用量はたかが知れているし、可読性などを考慮すれば大抵の場合はsync.WaitGroupを用いた単純な単純な並行化で十分だろう。
パイク氏は計測することと一緒に次のようにも述べている。
凝ったアルゴリズムはシンプルなそれよりバグを含みやすく、実装するのも難しい。シンプルなアルゴリズムとシンプルなデータ構造を使うべし。
計測結果とコードがあれば、「やらない」という選択肢も自信をもって取れるだろう。
おまけ
Wikipediaよりパイク氏のプログラミング5箇条(6箇条)を全文引用しておく。
ルール1: プログラムがどこで時間を消費することになるか知ることはできない。ボトルネックは驚くべき箇所で起こるものである。したがって、どこがボトルネックなのかをはっきりさせるまでは、推測を行ったり、スピードハックをしてはならない。
ルール2: 計測すべし。計測するまでは速度のための調整をしてはならない。コードの一部が残りを圧倒しないのであれば、なおさらである。
ルール3: 凝った(Fancy)アルゴリズムは{\displaystyle n}nが小さいときには遅く、
nはしばしば小さい。凝ったアルゴリズムは大きな定数を持っている。nが頻繁に大きくなることがわかっていないなら、凝ってはいけないnが大きくなるときでさえ、ルール2が最初に適用される)。ルール4: 凝ったアルゴリズムはシンプルなそれよりバグを含みやすく、実装するのも難しい。シンプルなアルゴリズムとシンプルなデータ構造を使うべし。
ルール5: データはすべてを決定づける。もし、正しいデータ構造を選び、ものごとをうまく構成すれば、アルゴリズムはほとんどいつも自明のものになるだろう。プログラミングの中心は、アルゴリズムではなくデータ構造にある。
ルール6: ルール6は存在しない。
参考
- Go Advent Calendar 2020
- https://pkg.go.dev/golang.org/x/perf/cmd/benchstat
- https://golang.org/cmd/trace/
- パイク: Cプログラミングに関する覚え書き
- Go言語のベンチマークでパフォーマンス測定 | by eureka, Inc.
- https://golang.org/cmd/go/#hdr-Testing_flags
- Go Benchmark Toolingで実行結果の可視化機能を利用する
- Goでワーカープールを15分で実装する方法
- Go 1.12で個人的に気になったところを触ってみた | 生涯未熟